图像物体分类
接下来我们继续学习基于Hobot CNN模型推理库之上的视觉应用。
机器人要感知周边环境,那就得确定看到的图像中都有什么,比如地上有一只猫,旁边有一个桌子之类的,这个猫和桌子就是具体的物体分类啦。
图像分类原理
如果是人来识别一只猫的话,似乎再简单不过了,无论黑猫、白猫还是花猫,我们一眼就可以看出来。
不过这件事对于机器人来讲可没有那么简单,为了能够让机器准确识别一只猫,无数学者可是研究了几十年啊,虽然还赶不上人类的智慧,但是这件事已经没有那么遥不可及了。
比如说我们要让机器识别图像中有一只猫,我们就得先教会机器什么是猫,对此我们就得把各种各样猫的照片给计算机看,目的就是让机器学习,看的越多,识别的也就越准。
我们那里找这么多猫的图片呢?
大家可能听说过一个著名的视觉对象数据库——ImageNet,里边有超过1400万张标注过的图像,2万多个类别,我们就可以利用这个庞大的数据库,找到很多猫的照片。
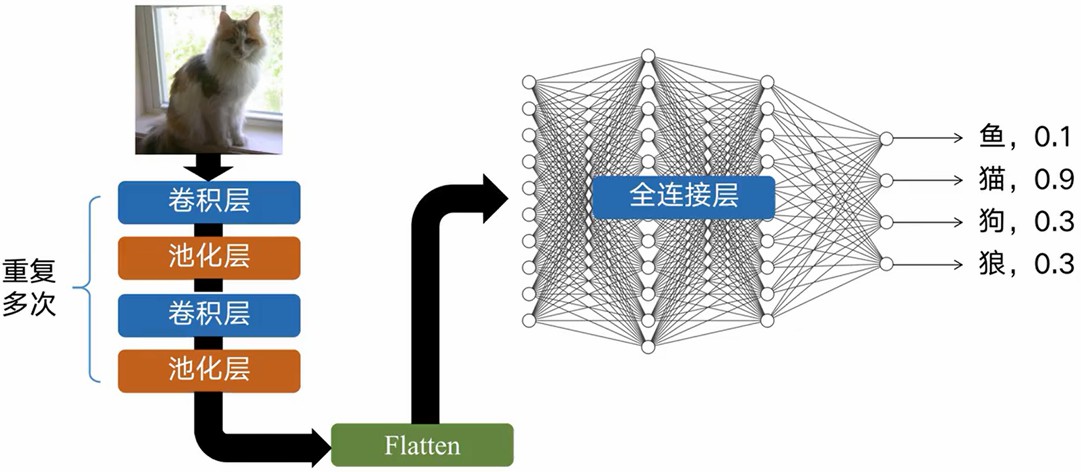
然后就搭建神经网络,把这些数据放进去训练了,调教出一套比较好的识别模型。
接下来把这套模型部署到机器人上,之后每当有一幅图像收到之后,就传到这个模型中,也就是模型推理,推理的结果就是类似这样的数据,概率最大的,也就是机器识别到的物体啦。
关于机器学习,理论众多,大家可以学习专门的课程,我们课上还是重点讲解在TogetherROS中的实现方法。
编程开发方法
我们来看这样一张图片,大家很快就可以发现这是一只斑马。

运行示例程序
我们如何用机器来识别它呢,大家先来运行这个案例,这是基于ImageNet数据集训练的模型,可以识别1000种常见的物体,我们看一下效果如何?

代码解析
test_mobilenetv1.py:
#!/usr/bin/env python3
from hobot_dnn import pyeasy_dnn as dnn
import numpy as np
import cv2
def bgr2nv12_opencv(image):
height, width = image.shape[0], image.shape[1]
area = height * width
yuv420p = cv2.cvtColor(image, cv2.COLOR_BGR2YUV_I420).reshape((area * 3 // 2,))
y = yuv420p[:area]
uv_planar = yuv420p[area:].reshape((2, area // 4))
uv_packed = uv_planar.transpose((1, 0)).reshape((area // 2,))
nv12 = np.zeros_like(yuv420p)
nv12[:height * width] = y
nv12[height * width:] = uv_packed
return nv12
def print_properties(pro):
print("tensor type:", pro.tensor_type)
print("data type:", pro.dtype)
print("layout:", pro.layout)
print("shape:", pro.shape)
def get_hw(pro):
if pro.layout == "NCHW":
return pro.shape[2], pro.shape[3]
else:
return pro.shape[1], pro.shape[2]
if __name__ == '__main__':
# test classification result
models = dnn.load('../models/mobilenetv1_224x224_nv12.bin')
# test input and output properties
print("=" * 10, "inputs[0] properties", "=" * 10)
print_properties(models[0].inputs[0].properties)
print("inputs[0] name is:", models[0].inputs[0].name)
print("=" * 10, "outputs[0] properties", "=" * 10)
print_properties(models[0].outputs[0].properties)
print("outputs[0] name is:", models[0].outputs[0].name)
# 打开图片
img_file = cv2.imread('./zebra_cls.jpg')
# 把图片缩放到模型的输入尺寸
# 获取算法模型的输入tensor 的尺寸
h, w = get_hw(models[0].inputs[0].properties)
des_dim = (w, h)
resized_data = cv2.resize(img_file, des_dim, interpolation=cv2.INTER_AREA)
nv12_data = bgr2nv12_opencv(resized_data)
# 模型推理
outputs = models[0].forward(nv12_data)
print("=" * 10, "Get output[0] numpy data", "=" * 10)
print("output[0] buffer numpy info: ")
print("shape: ", outputs[0].buffer.shape)
print("dtype: ", outputs[0].buffer.dtype)
# print("First 10 results:", outputs[0].buffer[0][:10])
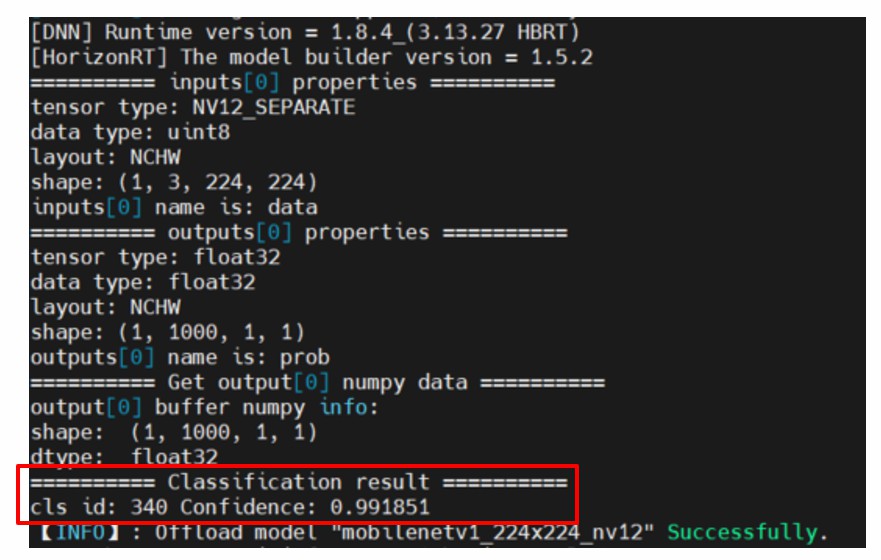
# 从输出结果中得到值最大的那个序号,比如 zebra 就是第 340 个值,应该大于 0.99
print("=" * 10, "Classification result", "=" * 10)
assert np.argmax(outputs[0].buffer) == 340
# 输出类别序号和预测概率值
print("cls id: %d Confidence: %f" % (np.argmax(outputs[0].buffer), outputs[0].buffer[0][np.argmax(outputs[0].buffer)]))
Mobilenetv2物体分类
用图片进行识别不太过瘾,毕竟是静态的图像,没问题,TogetherROS中还提供了实时物体分类的案例,我们继续来体验一下。

为了实时显示视觉识别的效果,这里我们需要启动TogetherROS中的一个web服务器,它会把视觉识别的实时效果,通过网络传输出来,我们直接在浏览器中就可以看到结果啦。也是便于我们开发调试的一个重要工具。
# 启动webserver服务
$ cd /opt/tros/lib/websocket/webservice/
$ chmod +x ./sbin/nginx && ./sbin/nginx -p .
运行例程:
$ source /opt/tros/setup.bash
$ cp -r /opt/tros/lib/dnn_node_example/config/ .
$ cp -r /opt/tros/lib/dnn_benchmark_example/config/runtime/ ./config/
$ ros2 launch /opt/tros/share/dnn_node_example/launch/hobot_dnn_node_example.launch.py config_file:=config/mobilenetv2workconfig.json image_width:=480 image_height:=272
在浏览器中登录192.168.1.10,就可以看到分类效果啦:

